Hydra, a precursor to GraphQL
This post was sparked by Lee Byron’s excellent writeup on how several Facebook projects (such as GraphQL) came about:
While my team spent much of 2013 working on core business solutions at HigherEducation.com, a domestic, contract software company spent over a year building and maintaining an API that made IPEDS (an open database for U.S. colleges) easier for our WordPress sites to build more engaging experiences on top of.
Post-launch, we started creating experiences with the API, but quickly ran into issues that went months without resolution.
“The API can’t scale past 5 sites. We have to rewrite it.”
Some enjoy rewriting others’ code (after all, they did it wrong, right!?), but there’s no joy to be had in delaying more important projects for something that you paid 💰 to be already be solved.
🗑 The Rewrite
Late 2013, we started from scratch, rewriting the contract company’s Ruby on Rails API & schema in 1/10th the time using Node + Express, settling on ~75ms response times 🔥.
Soon our API (with the uninspired name Hydra, since we started baking other features into it) was being used across dozens of sites without any performance issues at scale. That was, until we started creating more individualized, ambitious experiences…
📉 Snowflakes Don’t Scale
Each project using an API is naturally unique and eventually requires different data feeds.
Soon we were returning more data per-request just-in-case a data-point was needed, since adoption exploded within weeks.
Now, consumers were starting to run queries that could take several seconds due to greedy data-fetches being costly to query, normalize, transform, and render to the client.
🤔 The Re-Rewrite
At this point, in April 2014, I was kicking around ideas that, in my mind, would solve several architectural issues:
-
Introduce a Dictionary of _Terms. _(e.g. A school’s address would be called school.address).
-
Every data-point would be opt-in.
-
**Queries were composed & co-located **to data-points.
-
The **UI & Documentation is generated from each Term’s definition.
-
Terms are warehoused in a separate DB specific to the API for speed.
As the data came from SQL and would be fetched again with SQL, I tried out a few experiments before settling on the schema:
-
Term/Value store in MySQL. (Worst)
-
Term/Value store in PostgreSQL. (Better)
-
Each Term is a table. (Great, but eventually too many joins)
-
Grouping like-Terms into tables (e.g. Entities). (Best)
Naturally, relational data performed best in a relational database.
After a week of prototyping , I had a functioning demo of a dynamic API:
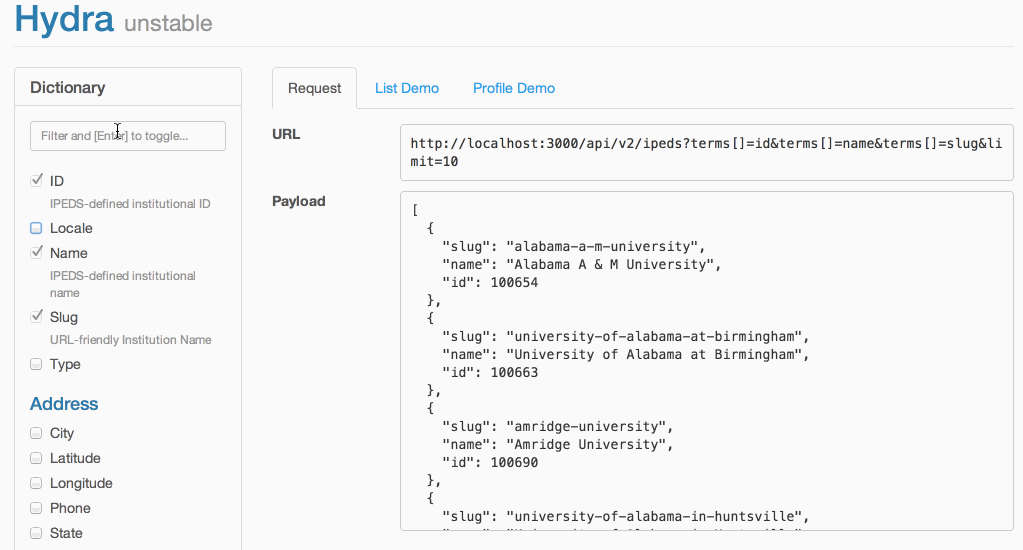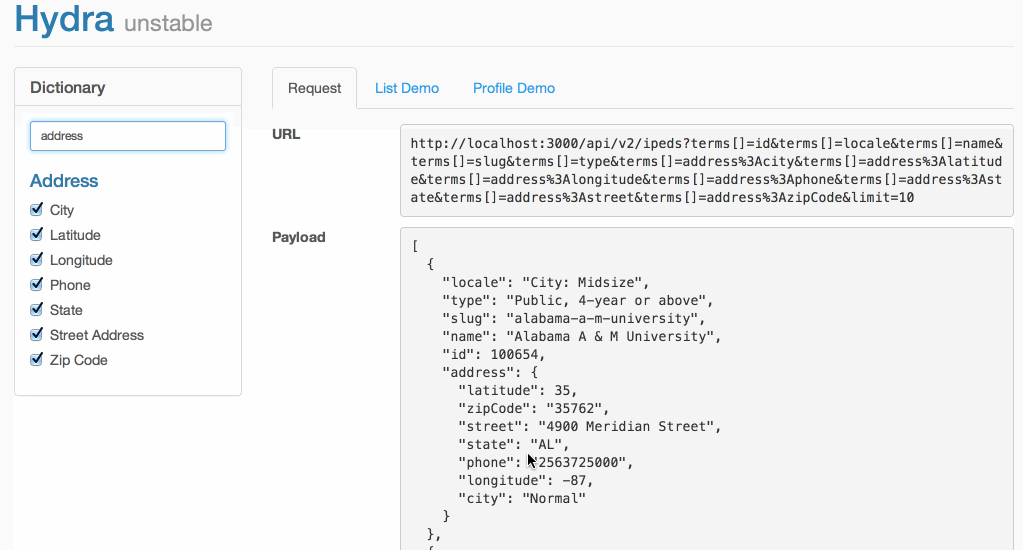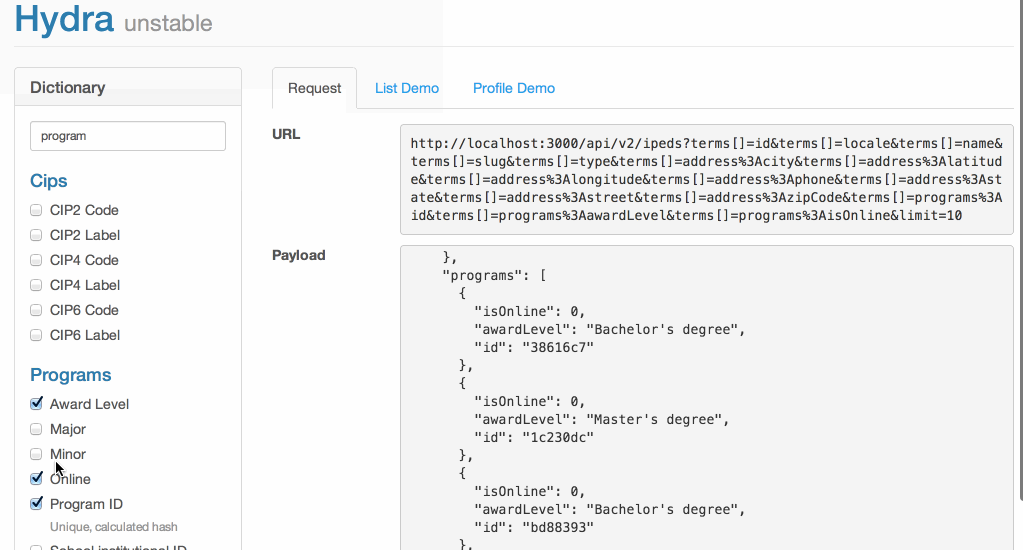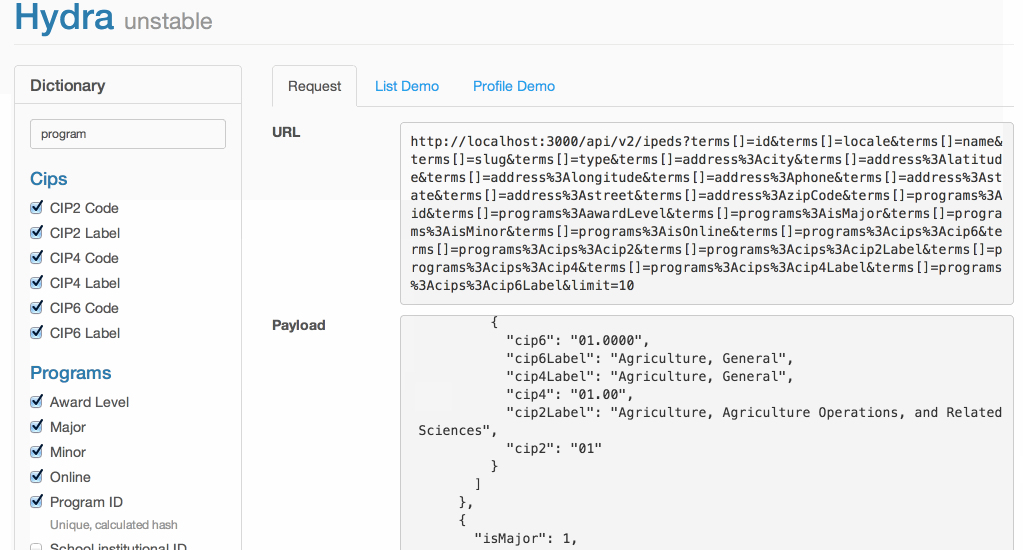
📖 Terms
Each term was responsible for defining:
-
The table and schema it required for warehousing. (This made migrations a cinch.)
-
How to fetch data for warehousing. (As a result, each Term could be updated independently.)
-
How to fetch data for the API, including referencing dependencies.
-
The UI for the consumer to generate an API URL from.
-
How to normalize the API response (e.g. trimming, capitalization).
For example, this is how the query, UI, and warehousing was handled for the state a school was located in:
👍 What We Did Right
-
Performance was incredible (~17ms), even when requesting most data-points. The previous rewrite could take 10 seconds due to the complexity of joins.
-
Making multiple queries per API call seems wrong, but performs better than expected, especially in Node + caching.
-
Warehousing complex data structures is helpful. This helped shave off tons of joins that we would’ve had to do otherwise had we kept the data in its original schema.
-
Colocating responsibilities to the Term reduces cognitive overhead. As in, managing the UI, warehousing, schema, for each term was simpler vs. having a dedicated admin, migrations folder, or similar.
-
Documentation must co-exist with the API. Generating & maintaining API docs separately (we used aglio) made keeping changes in sync difficult. With the rewrite, the UI became much of the documentation, as it is with GraphiQL.
👎 What We Did Wrong
-
Ignored the similarities that the path for the *Term *had to the JSON output. GraphQL seems so obvious in retrospect, in that it is visually similar to JSON.
-
Warehousing data is largely unnecessary if you aggressively cache & optimize queries per Term. This is where facebook/dataloader shines.
-
Validate the request first. The response was built as queries completed, so we’d often waste 9 to find the 10th had an invalid argument provided by the user.
-
Uncaught Exceptions can cause DOS downtime. Typically you want errors to be load and throw new Error(…) shows up real nicely in New Relic. But, one errant script can cause all instances of your app to crash before another comes back online. GraphQL correctly traps errors and makes them part of the response.
…Two Years Later…
Sadly, we abandoned that project in favor of other initiatives that, frankly, impacted users at a much larger scale. The tech was exciting, but the application wasn’t.
Today, we recognize & leverage GraphQL as the architectural successor to what we needed a few years earlier: a performant, version-less API centered around the needs of individual views, not their aggregate.
Thanks for making it this far! 😍
If you’d like to discuss improving “Developer Experience”, hit me up on Twitter or Github.